
如果你已经从第一章按部就班的学到了第 17 章,我相信你所认识的 C++知识已经超过了很多人,因为有学习的同学并没有耐心慢慢全面地学完 C++11 的全部知识,从 17 章 标准库特殊设施以及第 18 章 用于大型程序的工具、第 19 章 特殊工具与技术这三个单元被统称为高级主题,这些内容往往在大型工程中意义重大
首先介绍本章整体内容,tuple 类型、bitset 类型、正则表达式、随机数、进一步深入 IO 操作
#include<tuple>tuple 与 pair 有些类似,但是 tuple 支持多个元素,多种元素类型,在希望将一些数据组合成单一对象,但不想麻烦地自定义数据结构表示时很有用,tuple 是一个“快速而随意”的数据结构
定义格式为tuple<T1,T2,T3...>name;,使用构造函数初始化,或者在
tuple
内元素类型相同时使用参数列表进行初始化、或者使用make_tuple初始化
tuple 类型
int main(int argc, char **argv)
{
//成员被默认初始化
tuple<size_t, int, string> threeData;
//参数列表初始化内部容器类型
tuple<string, vector<double>, int, list<int>> s("hi", {12.0, 32., 43.}, 9, {2, 3});
//参数列表初始化tuple
// tuple<int, int, int> s1 = {1, 2, 3};//错误 tuple构造函数是explicit的
tuple<int, int, int> s2{1, 2, 3};
// make_tuple
auto s3 = make_tuple("12", 32, 34.f, 34.5);
// class std::tuple<const char *, int, float, double>
return 0;
}需要使用 get
模板,get<size_t>(tuple)对成员进行访问,tuple_size模板获取
tuple 内元素的个数、tuple_element模板可以获取 tuple
内元素的数据类型
//example2.cpp
int main(int argc, char **argv)
{
tuple<int, string, double> m_tuple{1, "12", 34.};
//取值
auto item1 = get<0>(m_tuple);
auto item2 = get<1>(m_tuple) + "[]";
auto item3 = get<2>(m_tuple) * 5;
cout << item1 << " " << item2 << " " << item3 << endl;
// 1 12[] 170
//赋值
get<0>(m_tuple) = 999;
cout << get<0>(m_tuple) << endl; // 999
// tuple_size模板
size_t size = tuple_size<decltype(m_tuple)>::value;
cout << size << endl; // 3
// tuple_element模板
tuple_element<1, decltype(m_tuple)>::type el = get<1>(m_tuple);
cout << el << endl; // 12
return 0;
}tuple 之间允许使用关系比较运算符==、<、>,本质为两个 tuple 中的元素相同位置的元素与另一个 tuple 相同位置元素比较,两两元素之间必须为可比较的
//example3.cpp
int main(int argc, char **argv)
{
tuple<int, int, int> t1{1, 2, 3};
tuple<int, int, int> t2{1, 2, 3};
tuple<int, int, int> t3{0, 1, 2};
tuple<string, int, int> t4{"hi", 2, 3};
// 错误 string与int不能比较
// cout << (t4 < t2) << endl;
cout << (t1 == t2) << endl; // 1
cout << (t1 > t3) << endl; // 1
cout << (t3 < t1) << endl; // 1
cout << (t3 == t1) << endl; // 0
return 0;
}可以借助容器或者数组实现
//example4.cpp
struct Pack
{
tuple<int, int> res[3];
};
Pack func1()
{
Pack pack;
tuple<int, int>(&res)[3] = pack.res;
get<0>(res[0]) = 1;
get<1>(res[0]) = 2;
get<0>(res[1]) = 1;
get<1>(res[1]) = 2;
get<0>(res[2]) = 1;
get<1>(res[3]) = 2;
return pack;
}
vector<tuple<int, int>> func2()
{
vector<tuple<int, int>> vec;
for (int i = 0; i < 3; i++)
{
vec.push_back(make_tuple(i, i + 1));
}
return vec;
}
int main(int argc, char **argv)
{
Pack pack = func1();
decltype(pack.res) &res = pack.res;
cout << get<0>(res[0]) << " " << get<1>(res[0]) << endl;
// 1 2
vector<tuple<int, int>> &&res1 = func2();
cout << get<0>(res1[0]) << " " << get<1>(res1[0]) << endl;
// 0 1
return 0;
}与标准容器一样,用 tuple 做参数时默认为拷贝
//example5.cpp
tuple<int, string> func1(const tuple<string, int> &m_tuple)
{
tuple<int, string> res;
get<0>(res) = get<1>(m_tuple);
get<1>(res) = get<0>(m_tuple);
return res;
}
int main(int argc, char **argv)
{
auto temp = make_tuple("hello", 10);
const auto &&res = func1(temp);
cout << get<0>(res) << " " << get<1>(res) << endl;
// 10 hello
return 0;
}已经学习过位运算的相关知识,标准库还定义了 bitset 类,使得位运算使用起来更为容易,能够处理超过最长整形类型大小的位集合
#include<bitset>bitset 是一个模板,与 array 类类似,有固定大小
编号从 0 开始的二进制位被称为低位、编号到 n-1 结束的二进制被称为高位
//example6.cpp
int main(int argc, char **argv)
{
bitset<10> b1; // n位全为0
bitset<64> b2(1ull); //使用unsigned long long初始化
bitset<128> b22(0xbeef);
bitset<128> b23(~0ull); // 64个1
//使用字符串初始化
string str = "010101010101";
bitset<32> b31(str);
cout << b31 << endl; // 00000000000000000000010101010101
bitset<32> b32(str, 0, str.size(), '0', '1'); //'0'为0 '1'为1
cout << b32 << endl; // 00000000000000000000010101010101
bitset<32> b33(str, 0, 3); //[ 0, 2 ]
cout << b33 << endl; // 00000000000000000000000000000010
bitset<32> b34(str, str.size() - 4); //末尾4位
cout << b34 << endl; // 00000000000000000000000000000101
try
{
bitset<32> b4(str, 0, str.size(), '0', 'g'); //有非g的字符
}
catch (invalid_argument e)
{
cout << e.what() << endl; // bitset::_M_copy_from_ptr
}
// C字符串初始化
const char *str1 = "010101000111";
bitset<32> b5(str1); //默认为[0,strlen(str1)-1]
cout << b5 << endl; // 00000000000000000000010101000111
bitset<32> b6(string(str1), 0, 1, '0', '1');
cout << b6 << endl; // 00000000000000000000000000000000
return 0;
}bitset 类模板支持功能丰富的二进制相关操作

bitset 支持统计其中的零一比特位,操作有 bitset.any()、bitset.all()、bitset.count()、bitset.size()、bitset.none()
//example7.cpp
int main(int argc, char **argv)
{
bitset<64> b(888ULL);
cout << b << endl;
// 0000000000000000000000000000000000000000000000000000001101111000
cout << b.any() << endl; // 1 是否存在1
cout << b.all() << endl; // 0 是否全为1
cout << b.count() << endl; // 6 有几个1
cout << b.size() << endl; // 64 bitset大小
cout << b.none() << endl; // 0 是否全为0
bitset<32> b1;
cout << b1 << endl;
// 00000000000000000000000000000000
cout << b1.any() << endl; // 0 是否存在1
cout << b1.all() << endl; // 0 是否全为1
cout << b1.count() << endl; // 0 有几个1
cout << b1.size() << endl; // 32 bitset大小
cout << b1.none() << endl; // 1 是否全为0
return 0;
}bitset 支持改变 bitset 内的内容,bitset.flip()、bitset.reset()、bitset.set()、bitset.test(),bitset[pos]
//example8.cpp
int main(int argc, char **argv)
{
bitset<10> b;
cout << b << endl; // 0000000000
//默认
b.flip(); //反转所有位
cout << b << endl; // 1111111111
b.reset(); //全置为0
cout << b << endl; // 0000000000
b.set(); //全置为1
cout << b << endl; // 1111111111
//指定下标
b.flip(0);
cout << b << endl; // 1111111110
b.set(0);
cout << b << endl; // 1111111111
b.set(1, 0); // index 1 value 0
cout << b << endl; // 1111111101
b.reset(0);
cout << b << endl; // 1111111100
//判断是bit 1
cout << b.test(0) << " " << b.test(2) << endl; // 0 1
//下标操作
cout << b << endl; // 1111111100
b[0] = 1;
cout << b << endl; // 1111111101
b[1] = b[0];
cout << b << endl; // 1111111111
b[0].flip();
cout << b << endl; // 1111111110
bool res = ~b[0];
cout << res << endl; // 1
return 0;
}bitset.to_ulong()与 bitset.to_ullong 操作,只有 bitset 的大小与 unsigned long 与 unsigned long long 内存大小相等时,才能调用这两个方法
//example9.cpp
int main(int argc, char **argv)
{
cout << sizeof(unsigned long) * 8 << endl; // 32bit
cout << sizeof(unsigned long long) * 8 << endl; // 64bit
bitset<32> b1;
unsigned long res1 = b1.to_ulong();
bitset<64> b2;
unsigned long long res2 = b2.to_ullong();
cout << b2.to_string() << endl;
// 0000000000000000000000000000000000000000000000000000000000000000
try
{
bitset<128> b3;
b3.set();
int res = b3.to_ulong(); // b3装不到ulong里
}
catch (overflow_error e)
{
cout << e.what() << endl; //_Base_bitset::_M_do_to_ulong
}
return 0;
}bitset
作为作为输入流时,其原理为先用临时的字符串流存储,然后用字符串对 bitset
进行了改变,在读取字符串时,遇到输入流结尾或者不是’0’或’1’时结束
bitset 作为输出流时也是将内容以字符串形式输出
//example10.cpp
int main(int argc, char **argv)
{
bitset<10> b1;
string s1 = "0101010011";
stringstream s;
s << s1;
s >> b1;
cout << b1 << endl; // 0101010011
return 0;
}请你用尽可能内存少数据存储 64 个同学的成绩是否通过的数据结构
//example11.cpp
class Data
{
private:
bitset<64> base;
function<bool(int)> check;
public:
Data(const function<bool(int)> &check) : check(check)
{
}
void set(int index, int score)
{
if (check(score))
{
base.set(index);
}
}
string to_string()
{
return base.to_string();
}
bool operator[](const int &index)
{
return base[index];
}
};
int main(int argc, char **argv)
{
Data data([](int score) -> bool
{ return score >= 60; });
cout << data.to_string() << endl;
// 0000000000000000000000000000000000000000000000000000000000000000
data.set(0, 45);
data.set(1, 78);
cout << data.to_string() << endl;
// 0000000000000000000000000000000000000000000000000000000000000010
cout << data[0] << " " << data[1] << endl;
// 0 1
return 0;
}可以发现第 17 章是很有趣的一章,因为在前面的章节内我们已经学习了关于 C++的大多数功能特性,再此应用起来也能够明白其内的原理
C++是支持正则表达式的,如果你还不知道正则表达式请查阅相关博客或者教学视频进行了解其理论基础与实际用法
#include<regex>正则表达式库组件

regex_match 用于匹配整个输入序列与表达式匹配,则返回 true
regex_search 用于如果输入序列中一个子串与表达式匹配,则返回 true

表达式基础
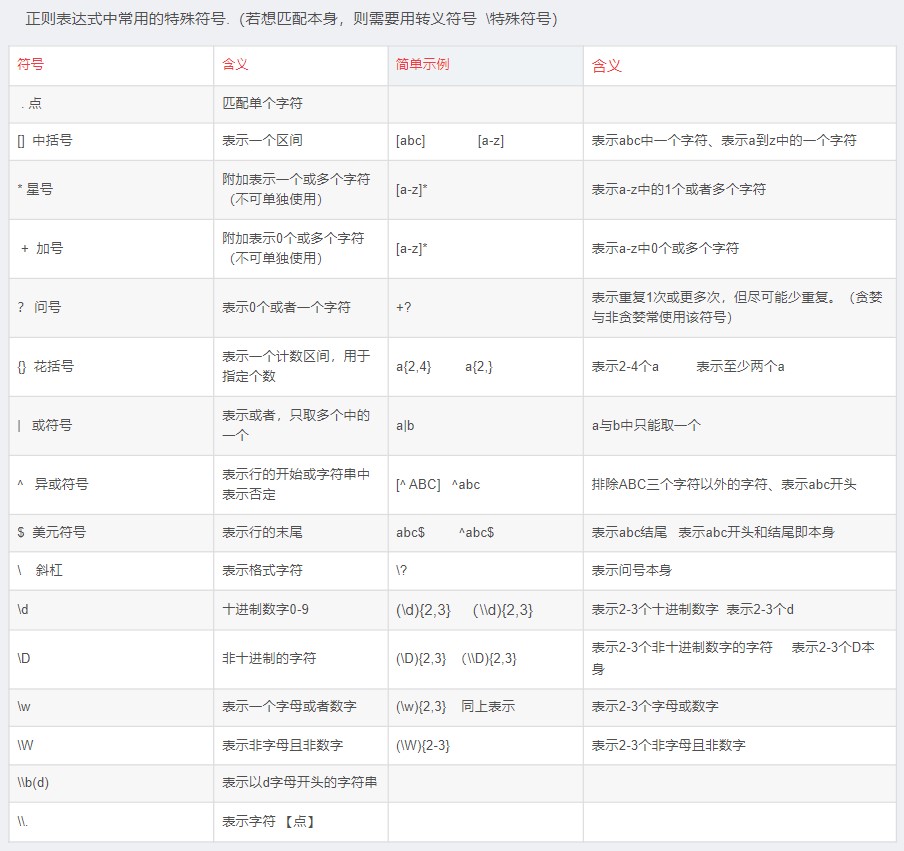
下面以[abc]wan表达式为模板,其表达式的含义为以 abc
中任意一个字符开头,且后面紧跟的序列为 wan
//example12.cpp
int main(int argc, char **argv)
{
string pattern("[abc]wan");
regex r(pattern);
smatch results;
string test = "cwanawanbwanwan";
regex_search(test, results, r);
cout << results.str() << endl; // cwan
const sregex_iterator end;
sregex_iterator iter(test.begin(), test.end(), r);
while (iter != end)
{
cout << iter->str() << endl; // cwan awan bwan
iter++;
}
return 0;
}正则表达式是一种语言,但是其有多种版本,这些都是历史遗留问题,C++允许在创建 regex 与 wregex 时指定正则表达式语法版本

//example13.cpp
int main(int argc, char **argv)
{
string s1 = "[acv]pp";
const char *s2 = "[acv]pp";
regex p1(s1, regex::icase);
p1 = s2;
regex p2 = p1;
p2.assign(s1, regex::optimize);
return 0;
}正则表达式本身可以视为一种简单程序设计语言,这种语言的解析不是 C++编译器解决的,所以有异常时,也是运行时异常而非编译错误
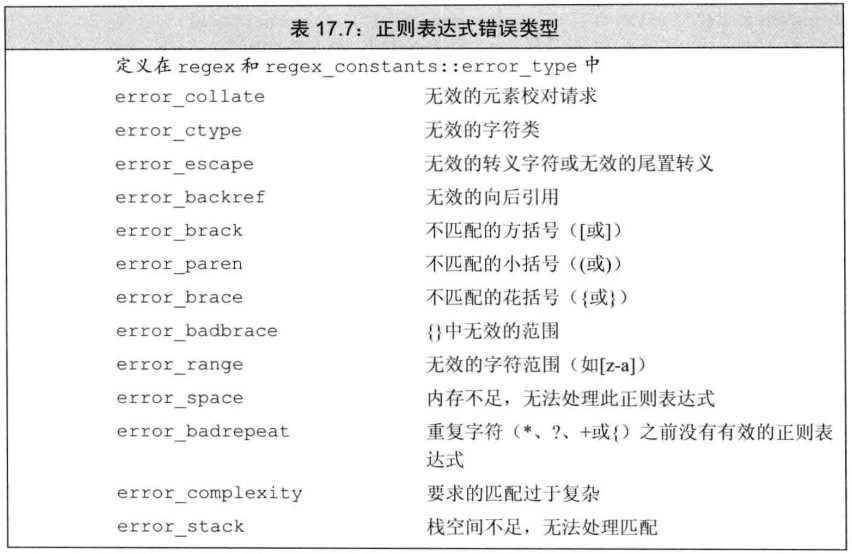
//example14.cpp
int main(int argc, char **argv)
{
try
{
regex r("[acv", regex::icase);
}
catch (regex_error e)
{
// Unexpected character in bracket expression.
cout << e.what() << endl;
}
cout << "hi" << endl; // hi
return 0;
}输入序列类型可以为,char 数据和 wchar_t 数据,字符可以保存在 string 或 char 数组中、宽字符版本,w_string 或 wchar_t 数组中
regex 默认为匹配 char 字符,如果操作宽字符要使用 wregex

//example15.cpp
int main(int argc, char **argv)
{
regex r1("[abc]ui");
smatch res1;
// regex_search("cui", res1, r1);
//错误 不应用smatch接收char序列的结果
string test = string("cui");
regex_search(test, res1, r1); //正确
cmatch res2;
regex_search("cui", res2, r1); //正确
wstring test2 = L"b你好";
wsmatch res3;
wregex r2(L"[abc]你好");
regex_search(test2, res3, r2);
// wcout.imbue(std::locale(""));
wcout << res3.str() << endl;
wchar_t ch = L'你';
cout << ch << endl;
return 0;
}有时需要找出一个序列中所有符号要求的子序列,这就需要使用 sregex_iterator、cregex_iterator、wsregex_iterator 和 wcregx_iterator

//example16.cpp
int main(int argc, char **argv)
{
string pattern("[^bc]ui");
string test = "buicuiruiuitui";
regex r(pattern, regex::icase);
for (sregex_iterator iter(test.begin(), test.end(), r), end_iter; iter != end_iter; ++iter)
{
cout << iter->str() << endl; // rui tui
}
return 0;
}我们会发现上面的匹配结果中并没有iui,为什么呢?因为在扫描
test 时有一个迭代器,每次从那个迭代器使用 regex_search
然后从开头进行匹配,匹配成功则将迭代器移动到符合要求的子串的后面,所以在buicuiruiuitui迭代器到uitui时匹配成功的子序列就是tui
本质上每个 sregex_iterator 指向一个 smatch,smatch 本身可以提供很多额外的信息

//example17.cpp
int main(int argc, char **argv)
{
string pattern("[^bc]ui");
string test = "buicuiruiuitui";
regex r(pattern, regex::icase);
for (sregex_iterator iter(test.begin(), test.end(), r), end_iter; iter != end_iter; ++iter)
{
if (iter->ready())
{
cout << iter->str() << " "
<< iter->prefix().str() << " "
<< iter->suffix().str() << endl;
// rui buicui uitui 此次的subffix会成为下次search的序列
// tui ui 当subffix为空串时结束
cout << iter->size() << endl; // 1 1
cout << iter->empty() << endl; // 0 0
cout << iter->length() << endl; // 3 3
cout << iter->position() << endl; // 6 11 匹配成功的子序列首字母下标
cout << iter->format("$0=>") << endl; // tui=>
}
}
return 0;
}一个正则表达式从语法上由多个子表达式共同组成
//example18.cpp
int main(int argc, char **argv)
{
regex r("([[:alnum:]]+)\\.(cpp|cxx|cc)$", regex::icase);
//[[:alnum:]]+ [a-z]+
//\\. .
//(cpp|cxx|cc)
//$
string test("dcsc.cpp dsc.cpp vfd.cxx fgbf.cc sdfc.cc");
smatch res;
regex_search(test, res, r);
//子表达式匹配结果
for (size_t i = 0; i < res.size(); i++)
{
cout << res.str(i) << endl;
// sdfc.cc
// sdfc
// cc
}
for (sregex_iterator iter(test.begin(), test.end(), r), end_iter; iter != end_iter; ++iter)
{
cout << iter->str() << endl; // sdfc.cc
}
return 0;
}根据 ECMAScript
标准,正则表达式(\\()?(\\d{3})(\\))?([-. ])?(\\d{3})([-. ]?)(\\d{4})
1、(\\()?表示可选的左括号
2、(\\d{3})表示三位数字
3、(\\))?表示可选的右括号
4、([-. ])?表示可选的- . 空格
5、(\\d{3})表示三位数字
6、([-. ]?)表示可选的- . 空格
7、(\\d{4})表示 4 位数字
仅仅拥有整个正则表达式是否匹配成功的信息是不足够的,smatch 内有 ssub_match 的信息,[0]表示整个匹配,[1]表示第一个子表达式匹配,以此类推

//example19.cpp
//因为phonePattern由8个子表达式组成,所以m有8个ssub_match元素
bool valid(const smatch &m)
{
if (m[1].matched)
{ //有左括号
return m[3].matched && (m[4].matched && m[4].str() == "-");
}
else
{
return !m[3].matched && m[4].str() == m[6].str();
}
}
int main(int argc, char **argv)
{
string phonePattern = "(\\()?(\\d{3})(\\))?([-. ])?(\\d{3})([-. ])?(\\d{4})";
regex r(phonePattern);
smatch m;
string s = "434-434-5423"; // valid: 434-434-5423
for (sregex_iterator iter(s.begin(), s.end(), r), end_iter; iter != end_iter; ++iter)
{
if (valid(*iter))
{
cout << "valid: " << iter->str() << endl;
}
else
{
cout << "not valid: " << iter->str() << endl;
}
}
return 0;
}regex_replace 用于在匹配时,将符合要求的子序列替换成其他指定的内容

//example20.cpp
int main(int argc, char **argv)
{
string phonePattern = "(\\()?(\\d{3})(\\))?([-. ])?(\\d{3})([-. ])?(\\d{4})";
regex r(phonePattern);
string s = "434-434-5423 434-434-5423";
string fmt = "$2.$5.$7"; //第2个表达式.第5个表达式.第7个表达式
string fmted = regex_replace(s, r, fmt);
cout << fmted << endl; // 434.434.5423 434.434.5423
return 0;
}这些标志可以传递给函数 regex_search、regex_match、smatch 的 format 成员
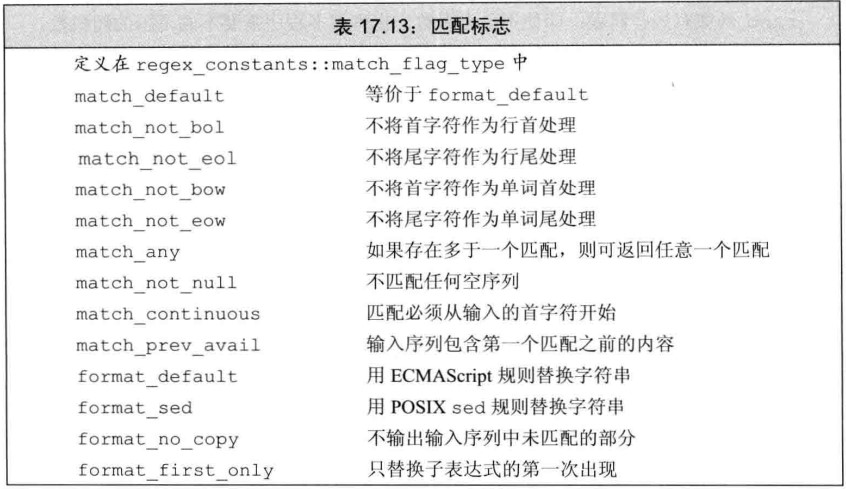
//example21.cpp
int main(int argc, char **argv)
{
string phonePattern = "(\\()?(\\d{3})(\\))?([-. ])?(\\d{3})([-. ])?(\\d{4})";
regex r(phonePattern, regex::icase);
string s = "434-434-5423 434-434-5523nvfdkjnvdk";
string fmt = "$2.$5.$7"; //第2个表达式.第5个表达式.第7个表达式
string fmted = regex_replace(s, r, fmt, std::regex_constants::format_no_copy);
cout << fmted << endl; // 434.434.5423434.434.5523
fmted = regex_replace(s, r, fmt);
cout << fmted << endl; // 434.434.5423 434.434.5523nvfdkjnvdk
sregex_iterator end_iter;
for (sregex_iterator iter(s.begin(), s.end(), r); iter != end_iter; ++iter)
{
cout << iter->str() << endl; // 434-434-5423 434-434-5523
}
for (sregex_iterator iter(s.begin(), s.end(), r, std::regex_constants::match_continuous); iter != end_iter; ++iter)
{
cout << iter->str() << endl; // 434-434-5423
}
return 0;
}在 C 语言中可以使用 rand 函数来生成伪随机数,但其并没有提供相关的封装与丰富的功能,在 C++中标准库对随机数引擎进行了封装
C 中的方法
//example22.cpp
#include <iostream>
#include <cstdlib>
#include <cstdio>
#include <ctime>
using namespace std;
int main(int argc, char **argv)
{
int n1 = rand();
cout << n1 << endl; // 41
//想要生成伪随机数要用srand
srand((unsigned)time(NULL));
cout << rand() << endl;
//产生随机数范围[m,n]
// int a=m+rand()%(n-m+1);
cout << 44 + rand() % (66 - 44 + 1) << endl; //[44,66]
return 0;
}C++中
#include<random>功能有随机数引擎(random-number engines)、随机数分布类(random-number distribution)

随机数引擎default_random_engine是函数对象类,定义了一个调用运算符,不接受参数然后返回一个随机
unsigned 整数

//example23.cpp
int main(int argc, char **argv)
{
default_random_engine e;
for (size_t i = 0; i < 10; ++i)
{
cout << e() << endl;
}
// 16807
// 282475249
// 1622650073
// 984943658
// 1144108930
// 470211272
// 101027544
// 1457850878
// 1458777923
// 2007237709
return 0;
}为了得到一个指定范围内的数,可以使用分布类型对象,uniform_int_distribution<T>(min,max)为均匀分布
//example24.cpp
#include <iostream>
#include <random>
using namespace std;
int main(int argc, char **argv)
{
uniform_int_distribution<unsigned> u(0, 9);
default_random_engine e;
for (size_t i = 0; i < 10; ++i)
{
cout << u(e) << endl;
}
// 0 1 7 4 5 2 0 6 6 9
return 0;
}分布对象和引擎对象的组合称为随机数发生器
在 C 中,rand 生成的数的范围在 0 至 RAND_MAX 之间,C++中随机数引擎使用 min 与 max 方法获得范围
//example25.cpp
int main(int argc, char **argv)
{
cout << 0 << " " << RAND_MAX << endl; // 0 32767
default_random_engine e;
cout << e.min() << " " << e.max() << endl; // 1 2147483646
return 0;
}下面有种令人迷惑的问题、default_random_engine 每次生成的数值序列都是相同的,犹如 default_random_engine 存储了一个数值序列一样,每生成一个,下一次就会返回后面的一个
//example26.cpp
vector<unsigned> get()
{
default_random_engine e;
vector<unsigned> vec;
uniform_int_distribution<unsigned> u(0, 9);
for (int i = 0; i < 10; i++)
{
vec.push_back(u(e));
}
return vec;
}
template <typename T>
void print(const vector<T> &vec)
{
for (auto item : vec)
{
cout << item << " ";
}
cout << endl;
}
int main(int argc, char **argv)
{
vector<unsigned> vec1 = get();
vector<unsigned> vec2 = get();
print(vec1); // 0 1 7 4 5 2 0 6 6 9
print(vec2); // 0 1 7 4 5 2 0 6 6 9
return 0;
}怎么解决这种问题呢,可以将模板引擎定义为 static 的,这样就会取同一个引擎中不同的序列了
//example27.cpp
vector<unsigned> get()
{
static default_random_engine e;
vector<unsigned> vec;
static uniform_int_distribution<unsigned> u(0, 9);
for (int i = 0; i < 10; i++)
{
vec.push_back(u(e));
}
return vec;
}
int main(int argc, char **argv)
{
vector<unsigned> vec1 = get();
vector<unsigned> vec2 = get();
print(vec1); // 0 1 7 4 5 2 0 6 6 9
print(vec2); // 3 5 8 0 0 5 6 0 3 0
//每次get都是不同的序列
return 0;
}种子就是一个数值,引擎可以利用它从序列中一个新位置重新开始生成随机数,为两种设置种子的方式,在创建引擎时提供种子,调用引擎的 seed 成员
//example28.cpp
int main(int argc, char **argv)
{
default_random_engine e1; //默认种子
default_random_engin e2(23434); //使用给定的种子值
default_random_engine e3;
// e1 e3将会生成相同的数值序列 因为其种子值相同
//使用seed重新设置新的种子值
e3.seed(434);
return 0;
}那么如何使得运行时设置的种子是不确定的呢?最好的办法是使用ctime内的
time
函数,返回从一个特定时刻到当前经过了多少秒,其接受单个指针参数,它指向用于写入时间的数据结构,如果指针为空,则简单地返回时间
//example29.cpp
int main(int argc, char **argv)
{
unsigned i = time(nullptr);
for (int i = 0; i < 10000; i++)
{
for (int i = 0; i < 100; i++)
{
if (i == 99)
{
cout << i << endl;
}
}
}
unsigned j = time(nullptr);
cout << i << " " << j << endl; // 1658727833 1658727836
// time返回以秒计的时间
default_random_engine e(time(nullptr));
return 0;
}要注意的时,在很短的间隔内如果多次调用 time 其可能返回的数值是相同的,所以要小心,以防多次设置了相同的种子造成,意想不到的结果

新标准库定义了 20 种分布类型,详情请见术语表章节的随机数部分
1、生成随机实数
uniform_int_distribution<double> u(min,max)
//example30.cpp
#include <iostream>
#include <random>
using namespace std;
int main(int argc, char **argv)
{
default_random_engine e;
uniform_real_distribution<double> u(0, 1);
//使用默认模板实参
uniform_real_distribution<> u1(0, 1); //默认生成double
for (size_t i = 0; i < 10; ++i)
{
cout << u1(e) << endl;
}
// 0.131538 0.45865 0.218959 0.678865 0.934693 0.519416 0.0345721 0.5297 0.00769819 0.0668422
return 0;
}2、非均匀分布
//example31.cpp
int main(int argc, char **argv)
{
default_random_engine e; //生成随机整数
normal_distribution<> n(4, 1.5); //均值为4 标准差为1.5
vector<unsigned> vec(9); // 9个0
for (size_t i = 0; i != 200; ++i)
{
unsigned v = lround(n(e)); //舍入到最近的整数
if (v < vec.size()) //在范围内
{
++vec[v];
}
}
for (size_t j = 0; j != vec.size(); ++j)
{
cout << j << ": " << string(vec[j], '*') << endl;
}
// 0: ***
// 1: ********
// 2: ********************
// 3: **************************************
// 4: **********************************************************
// 5: ******************************************
// 6: ***********************
// 7: *******
// 8: *
return 0;
}可见打印结果不是完美对称的,不符合均匀分布
3、伯努利分布
bernoulli_distribution 是一个普通类不是模板,其返回一个 bool 值,它返回 true 的概率为 0,.5
//example32.cpp
int main(int argc, char **argv)
{
default_random_engine e;
bernoulli_distribution b;
size_t count_true = 0, count_false = 0;
for (size_t i = 0; i < 10000; i++)
{
bool res = b(e);
if (res)
++count_true;
else
++count_false;
}
cout << count_true << " " << count_false << endl; // 4994 5006接近1:1
//还可以调整返回true的概率
bernoulli_distribution b1(0.55); //返回true/false 55/45
return 0;
}关于随机分布还有很多,可以查阅术语表章节或者查看其他资料进行学习
在前面的章节中已经学习到关于 IO 的一些操作,例如标准输入输出流、文件输入输出流、以及字符串流等相关操作,在此将会学习三个关于 IO 库的特性:格式控制、未格式化 IO、随机访问
如果有学习过 C 语言的话,我们知道 printf、sprintf、scanf 这些函数是支持进行内容格式化的,下面是一个简单的例子
//example33.cpp
#include <iostream>
#include <cstdio>
using namespace std;
int main(int argc, char **argv)
{
int a;
double b;
scanf("%d %lf", &a, &b);
getchar(); //获取回车
printf("%d,%lf\n", a, b);
char ch;
ch = getchar();
return 0;
}在 C++是否支持类似的内容呢?这就需要进行学习探索了
每个 iostream 对象维护了一个格式状态控制 IO 如何格式化细节,例如整形值是几进制、浮点值的精度、一个输出元素的宽度等
操纵符(manipulator)来修改流的格式状态,如 endl
就是一个操纵符,不仅仅是个普通的值,它输出一个换行符并刷新缓冲区
iostream 中的操纵符

iomanip 中的操纵符

boolalpha 与 noboolalpha
//example34.cpp
int main(int argc, char **argv)
{
cout << true << " " << false << endl; // 1 0
cout << boolalpha;
cout << true << " " << false << endl; // true false
cout << noboolalpha;
cout << true << " " << false << endl; // 1 0
cout << boolalpha << true << noboolalpha << endl; // true
return 0;
}整形数值默认输出十进制格式,可以使用 hex、oct、dec
将其改为十六进制、八进制、十进制
hex、oct、dec 只影响整型,对浮点值无影响
//example35.cpp
int main(int argc, char **argv)
{
cout << 12 << endl; // 12
cout << oct << 12 << endl; // 14
cout << hex << 12 << endl; // c
cout << dec; //改回十进制
cout << 12 << endl; // 12
return 0;
}用于显示进制的前导部分
1、前导 0x 为十六进制
2、前导 0 为八进制
3、无前导字符串表示十进制
关于十六进制的 0x 与 0X 可以使用 uppercase 与 nouppercase 控制
//example36.cpp
int main(int argc, char **argv)
{
cout << showbase;
cout << oct << 12 << endl; // 014
cout << hex << 12 << endl; // 0xc
cout << dec << 12 << endl; // 12
cout << uppercase << hex << 12 << dec << nouppercase << endl; // 0XC
cout << noshowbase;
return 0;
}浮点数输出有三种格式
1、以多高精度(多少个数字)打印浮点数
2、数值是打印为十六进制、定点十进制、科学计数法
3、当小数部分没有浮点值是否打印小数点
可以调用 IO 对象的 precision 成员或者使用 setprecision 操纵符
操纵符 setprecision 和其他接收参数的操纵符都定义在头文件 iomanip 中
//example37.cpp
#include <iostream>
#include <iomanip>
using namespace std;
int main(int argc, char **argv)
{
cout << cout.precision() << endl; // 6
cout << 23.3242345 << endl; // 23.3242
//设置精度
cout.precision(12);
cout << 1.123456789012 << endl; // 1.12345678901
// setprecision操纵符
cout << setprecision(6);
cout << cout.precision() << endl; // 6
return 0;
}scientific 科学计数法、fixed 定点十进制、hexfloat 浮点数十六进制、defaultfloat 恢复默认状态
//example38.cpp
int main(int argc, char **argv)
{
cout << 142.421 << endl; // 142.421
cout << scientific << 142.421 << endl; // 1.424210e+002
cout << fixed << 142.421 << endl; // 142.421000
cout << hexfloat << 124.421 << endl; // 8.00532e-307
cout << defaultfloat;
cout << 142.421 << endl; // 142.421
return 0;
}showpoint 与 noshowpoint 操纵当小数部分全为 0 时是否还输出小数部分
//example39.cpp
int main(int argc, char **argv)
{
cout << 10.0 << endl; // 10
cout << showpoint << 10.0 << endl; // 10.0000
cout << noshowpoint; //恢复
return 0;
}1、setw 指定下一个数字或字符串值得最小空间
2、left 表示左端对齐输出
3、right 表示右对齐输出、右对齐是默认格式
4、internal
控制负数得符号位置,左对齐符号、右对齐值,用空格填满所有中间空间
5、setfill 指定一个字符代替默认的空格来补白输出
//example40.cpp
int main(int argc, char **argv)
{
//至少12个空
cout << setw(12) << 23 << endl; //" 23"
//左对齐
cout << setw(12) << left << 23
<< setw(12) << 34 << endl; //"23 34 "
cout << right; //恢复默认右对齐
cout << internal << setw(12) << -234 << endl; //"- 234"
//自定义填充
cout << setfill('#') << setw(12) << right << 23 << endl; //"##########23"
cout << setfill(' '); //恢复默认填充
return 0;
}默认情况下,输入运算符会忽略空白符(空格符、制表符、换行符、换纸符、回车符)
一下程序,输入a b c cc\nfd会输出abcccfd
//example41.cpp
int main(int argc, char **argv)
{
char ch;
while (cin >> ch)
{
cout << ch;
}
return 0;
}skipws 与 noskipws 可以控制是否跳过空白符,使用 noskipws 后输入什么内容就会输出什么内容
//example42.cpp
int main(int argc, char **argv)
{
cin >> noskipws;
char ch;
while (cin >> ch)
{
cout << ch;
}
return 0;
}什么是格式化与未格式化,在之前使用<<或>>都是根据读取或写入的数据类型来进行格式化的,未格式化
IO(unformatted IO)将流当坐字节序列处理
单字节低层 IO 操作

//example43.cpp
int main(int argc, char **argv)
{
char ch;
cin.get(ch);
// cout << ch << endl;
cout.put(ch);
cin.get(); //读取\n
int ascii_code = cin.get(); // c
cout << ascii_code << endl; // 9
cin.putback(ascii_code); //检查流第一个字节与ascii_code是否相同,相同则跳过
ch = cin.peek(); //字节流第一个字节
cout << ch << endl; // c
cin.unget(); //向后移动一个字节即跳过一个字节
return 0;
}在头文件 cstdio 中定义了名为 EOF 的 const,可以检测从 get 返回的值是否为文件尾
//example44.cpp
int main(int argc, char **argv)
{
stringstream io;
io << "c++";
char ch;
while ((ch = io.get()) != EOF)
{
cout.put(ch); // c++
}
return 0;
}多字节低层 IO 操作

get 与 getline 有区别,两个函数一直读取数据,直至 已读取了 size-1 个字符、遇到了文件尾、遇到了分隔符,差别在于 getline 会丢弃分隔符
//example45.cpp
int main(int argc, char **argv)
{
stringstream io;
io << "helloworld";
// is.get(sink,size,delim)
char str[20];
io.get(str, 5, 'e');
cout << str << endl; // h
// getline(sink,size,delim)
io.getline(str, 5, 'w');
cout << str << endl; // ello io内的w被丢弃
// read(sink,size)
io.read(str, 4);
cout << str << endl; // orld
// is.gcount()
cout << io.gcount() << endl; // 4 上次未格式化读取的字节数
// os.write(source,size)
io.write(string("c++").c_str(), 3);
io.getline(str, 4);
cout << str << endl; // c++
// is.ignore(size,delim)
stringstream sio("hello");
sio.ignore(4, 'l');
char temp[10];
sio.read(temp, 2);
temp[2] = '\0';
cout << temp << endl; // lo
return 0;
}使用 gcount 来确定最后一个未格式化输入操作读取了多少个字符 ,如果调用 gcount 前使用了 peek、unget 或 putback,则 gcount 返回 0
//example46.cpp
int main(int argc, char **argv)
{
stringstream io;
io << "123456789";
char str[10];
io.getline(str, 100);
cout << str << endl; // 123456789
cout << io.gcount() << endl; // 9
return 0;
}在之前几个例子中我们都在使用 stringstream 但是当从中 read 内容,其中的内容并不会在流中消失,就是内部有个定位指针,其默认只会向后移动,没读取一个字节就像后移动一个位置,但是例如访问文件时,往往需要进行随机访问,标准库提供了定位(seek)到流中给定位置以及告诉(tell)我们当前的位置
要注意的是,istream 和 ostream 类型通常并不支持随机访问,大多数情况下用于 fstream 和 sstream 类型
seek 和 tell 函数

//example47.cpp
int main(int argc, char **argv)
{
stringstream io;
io << "helloworld";
// g版本用于输入流 p版本用于输出流
// tellg tellp
size_t pos = io.tellg();
cout << pos << endl; // 0
pos = io.tellp();
cout << pos << endl; // 10
// seekg seekp
io.seekg(0);
io.seekp(10);
io.seekg(1, io.beg);
cout << io.tellg() << endl; // 1
io.seekg(-1, io.cur);
cout << io.tellg() << endl; // 0
io.seekp(-1, io.cur);
cout << io.tellp() << endl; // 9
io.seekp(1, io.cur);
cout << io.tellp() << endl; // 10
return 0;
}总之 g 就是输入流的标记,p 就是输出流的标记,seek 与 tell 是在调整标记的位置与告诉标记的所在位置,在每个流中只维护单一的标记,如果一个流关联了输出流也关联了输入流则有 g 标记也有 p 标记
标记的类型为stream::pos_type,可以使用相应流数据类型的标记类型对标记进行临时存储等操作
//example49.cpp
int main(int argc, char **argv)
{
stringstream io;
io << "helloworld";
stringstream::pos_type mark = io.tellp();
cout << mark << endl; // 10
return 0;
}创建一个文件,写入内容,再将文件内的内容拷贝到另一个文件中
//example50.cpp
int main(int argc, char **argv)
{
fstream file1("1.iofile");
fstream file2("2.iofile");
if (file1.fail() || file2.fail()) //检查文件是否存在
{
cout << "create new file" << endl;
file1.open("1.iofile", fstream::ate | fstream::out);
file2.open("2.iofile", fstream::ate | fstream::out);
file1.close(), file2.close();
file1.open("1.iofile");
file2.open("2.iofile");
}
file1 << "helloworld" << flush;
//将file1内容拷贝的file2
file1.seekg(0, file1.beg);
cout << file1.tellg() << endl; // 0
cout << file2.tellp() << endl; // 0
char buffer[128];
while (file1.good() && !file1.eof())
{
file1.get(buffer, 128);
static size_t size;
size = file1.gcount();
cout << size << endl; // 10
file2.write(buffer, size);
}
return 0;
}到此我们对 C++的特殊功能有了更近一步的了解,这些功能都是在特定的场景下才能展现作用,使得开发效率更高,关于 IO 的内容到此也学习完毕了,后面的章节不再会介绍 IO 相关的内容了